

Pelatihan dan Sertifikasi BNSP – Di era digital yang berkembang pesat, data scientist menjadi salah satu aset paling berharga dalam proses pengambilan keputusan di berbagai sektor. Setiap hari, miliaran data dihasilkan dari aktivitas manusia dan sistem digital di seluruh dunia. Data tersebut menciptakan peluang besar bagi siapa pun yang mampu mengolah dan memanfaatkannya secara efektif. Namun, data mentah sering kali bersifat acak, tidak terstruktur, dan sulit digunakan secara langsung. Karena itu, dibutuhkan keahlian seorang Data Scientist untuk mengubah data mentah menjadi informasi yang bermakna. Peran ini membuat profesi Data Scientist semakin dibutuhkan di berbagai bidang kerja modern. Mereka tidak hanya membaca data, tetapi juga menafsirkan pola dan tren yang tersembunyi. Hasil analisis inilah yang menjadi dasar dalam merancang strategi dan pengambilan keputusan yang lebih efektif.
Melalui Pelatihan dan Sertifikasi BNSP Data Scientist di AMD Academy, kamu akan belajar mengelola data dari tahap awal hingga analisis akhir. Pelatihan ini mencakup data pre-processing, klasifikasi data, serta penerapan hasil analisis menjadi wawasan strategis yang siap digunakan. Setelah menyelesaikan pelatihan, kamu akan memperoleh sertifikasi resmi dari BNSP sebagai bukti kompetensi profesional yang diakui secara nasional.
Data Scientist, Skill yang Semakin Banyak Dibutuhkan Masa Kini
Profesi Data Scientist telah berkembang menjadi salah satu peran paling dicari di dunia kerja modern. Di era digital saat ini, hampir setiap industri menghasilkan data dalam jumlah besar yang memerlukan analisis mendalam agar dapat dimanfaatkan secara optimal. Tak heran, permintaan akan tenaga ahli di bidang data terus meningkat. Perusahaan dari berbagai sektor, seperti teknologi, keuangan, dan kesehatan, kini menyadari pentingnya analisis data. Dengan analisis yang tepat, mereka dapat menemukan pola tersembunyi di balik informasi yang kompleks. Hasilnya, perusahaan mampu mengambil keputusan yang lebih strategis dan berbasis bukti.
Seorang Data Scientist memiliki peran penting dalam mengekstrak wawasan berharga dari data mentah yang tersebar dalam berbagai format dan sumber. Mereka tidak hanya bekerja dengan angka, tetapi juga dengan teks, gambar, dan suara. Semua jenis data itu perlu diolah untuk menemukan hubungan serta pola yang bermakna. Dalam proses ini, mereka menggunakan teknik statistik, algoritma pemodelan, dan machine learning. Pendekatan tersebut membantu memprediksi tren, mengidentifikasi anomali, serta mengembangkan solusi inovatif bagi masalah bisnis yang kompleks.
Di dunia bisnis yang sangat kompetitif, kehadiran Data Scientist menjadi nilai tambah yang besar. Mereka membantu perusahaan memahami perilaku pelanggan, merancang strategi pemasaran yang efektif, serta meningkatkan efisiensi operasional. Sebagai contoh, perusahaan ritel dapat menggunakan analisis data untuk menentukan produk paling diminati, waktu terbaik meluncurkan promosi, dan cara mengoptimalkan rantai pasokan. Semua ini membuktikan bahwa kemampuan menganalisis dan menginterpretasi data menjadi faktor penting dalam kemajuan perusahaan di era digital.
Cakupan Kerja Data Scientist, Apa Saja Tugasnya?

Menjadi seorang Data Scientist tidak hanya sebatas melakukan analisis data. Faktanya, pekerjaan seorang Data Scientist mencakup proses yang luas dan komprehensif. Mulai dari mengumpulkan data mentah hingga menyampaikan hasil analisis kepada pemangku kepentingan. Mereka menjadi ujung tombak dalam membantu perusahaan mengubah data yang berantakan menjadi wawasan bernilai. Hasil analisis tersebut kemudian digunakan untuk mendukung keputusan strategis bisnis. Berikut adalah beberapa tugas utama yang biasanya dilakukan oleh seorang Data Scientist:
1. Pengumpulan Data: Mengakses Berbagai Sumber Data
Tugas pertama seorang Data Scientist adalah mengumpulkan data dari berbagai sumber yang relevan. Data bisa berasal dari database internal perusahaan, API (Application Programming Interface), sistem pelacakan pengguna, hingga teknik web scraping untuk mendapatkan data dari situs web eksternal. Proses ini membutuhkan keahlian teknis yang mendalam, termasuk kemampuan dalam menggunakan bahasa pemrograman seperti SQL, Python, atau R untuk mengekstraksi data. Pengumpulan data ini harus dilakukan dengan sangat hati-hati, karena data yang tidak akurat atau tidak lengkap akan memengaruhi kualitas analisis yang dilakukan di tahap selanjutnya.
Di era big data, Data Scientist sering kali harus bekerja dengan data yang sangat besar dan tersebar di berbagai platform yang berbeda. Tantangan dalam pengumpulan data ini tidak hanya soal volume, tetapi juga kecepatan dan keberagaman data yang dikumpulkan. Oleh karena itu, kemampuan untuk mengakses dan mengelola data dari berbagai sumber merupakan keterampilan penting yang harus dikuasai oleh seorang Data Scientist.
2. Pre-processing Data: Mempersiapkan Data untuk Analisis
Setelah data terkumpul, tahap berikutnya adalah melakukan pre-processing, atau dikenal sebagai tahap pembersihan dan persiapan data. Proses ini sangat penting karena data mentah sering kali mengandung banyak kesalahan, seperti nilai yang hilang (missing values), data yang duplikat, atau format yang tidak konsisten. Data Scientist harus mampu membersihkan data tersebut agar siap digunakan untuk analisis lebih lanjut. Langkah-langkah dalam pre-processing data meliputi:
- Menghapus atau menangani data yang hilang (missing values)
- Menghilangkan data yang duplikat atau redundan
- Mengonversi data ke dalam format yang seragam agar dapat diproses dengan algoritma statistik atau machine learning
- Normalisasi data atau pengubahan skala data agar hasil analisis lebih akurat
Tahap ini merupakan fondasi dari keseluruhan proses analisis, karena kualitas data yang baik akan memberikan hasil yang lebih valid dan dapat diandalkan.
3. Analisis Data: Menemukan Wawasan dari Data Mentah
Setelah data siap, tugas utama dari seorang Data Scientist adalah melakukan analisis data. Analisis ini bisa sangat beragam tergantung dari tujuan proyeknya, mulai dari analisis deskriptif untuk memahami pola-pola dasar dalam data, hingga analisis prediktif yang menggunakan algoritma machine learning dan deep learning untuk meramalkan tren masa depan.
Data Scientist harus mampu menggunakan metode statistik dan teknik komputasi yang canggih untuk menemukan pola yang tersembunyi dalam data. Dalam banyak kasus, mereka menggunakan algoritma machine learning untuk membuat model prediksi, yang memungkinkan perusahaan untuk meramalkan hasil berdasarkan data historis. Contoh umum penerapan analisis ini termasuk memprediksi perilaku pelanggan, mengidentifikasi segmen pasar yang berpotensi tumbuh, atau mendeteksi anomali yang dapat mengindikasikan adanya potensi risiko atau masalah.
Tidak hanya itu, Data Scientist juga sering menggunakan teknik unsupervised learning untuk mengelompokkan data ke dalam kategori yang lebih terstruktur, seperti klasterisasi pelanggan berdasarkan kebiasaan pembelian mereka.
4. Visualisasi Data: Menyampaikan Hasil Analisis dengan Jelas
Setelah wawasan diperoleh dari data, langkah terakhir dalam proses kerja Data Scientist adalah menyajikan hasil analisis dalam bentuk yang mudah dipahami. Kemampuan untuk membuat visualisasi data yang menarik dan informatif sangat penting, karena tidak semua orang di perusahaan memiliki latar belakang teknis yang kuat.
Data Scientist harus mampu mengomunikasikan hasil analisis dengan jelas kepada para pemangku kepentingan, seperti manajer atau eksekutif, agar mereka dapat memahami temuan-temuan yang diperoleh dan menerapkannya dalam strategi bisnis. Visualisasi data sering kali menggunakan grafik, bagan, peta interaktif, hingga dashboard yang dapat diakses secara real-time oleh pengguna yang tidak memiliki keahlian teknis.
Dengan keterampilan dalam visualisasi data, Data Scientist dapat memberikan pandangan yang lebih jelas mengenai data yang kompleks, sehingga memudahkan pengambilan keputusan berbasis data di tingkat perusahaan.
Mengelola Data Mentah Menjadi Data yang Siap untuk Digunakan

Dalam dunia data science, data mentah sering kali belum siap untuk digunakan langsung dalam analisis. Data mentah biasanya mengandung banyak masalah seperti ketidakkonsistenan, duplikasi, dan missing values yang bisa mengakibatkan hasil analisis yang salah atau menyesatkan. Oleh karena itu, mengelola data mentah menjadi salah satu tahapan paling penting dalam proses analisis data. Tahapan ini dikenal dengan istilah data pre-processing dan bertujuan untuk mempersiapkan data mentah menjadi bentuk yang bersih, terstruktur, dan siap digunakan untuk analisis lebih lanjut.
Mengelola data mentah dengan benar akan meningkatkan kualitas analisis data dan memastikan bahwa model yang dibangun dapat memberikan hasil yang akurat dan dapat diandalkan. Berikut adalah langkah-langkah kunci dalam proses pengolahan data mentah:
1. Pembersihan Data (Data Cleaning)
Langkah pertama dalam mengelola data mentah adalah melakukan data cleaning atau pembersihan data. Proses ini melibatkan identifikasi dan penghapusan data yang tidak relevan, rusak, atau duplikat. Misalnya, dalam sebuah dataset pelanggan, mungkin ada entri yang berisi data yang salah ketik, alamat email yang tidak valid, atau nomor telepon yang tidak sesuai format.
Pembersihan data memastikan bahwa hanya data yang valid dan relevan yang digunakan dalam analisis, sehingga mengurangi risiko kesalahan. Tanpa pembersihan data yang tepat, analisis bisa menjadi tidak akurat karena data yang cacat atau salah akan memengaruhi hasil akhir. Oleh karena itu, langkah ini menjadi sangat penting sebelum melanjutkan ke tahap analisis yang lebih kompleks.
Teknik pembersihan data meliputi:
- Menghapus atau memperbaiki data yang hilang (missing values)
- Mengidentifikasi dan menghilangkan data duplikat
- Mengoreksi kesalahan pengetikan atau kesalahan entri data
2. Transformasi Data (Data Transformation)
Setelah data dibersihkan, langkah berikutnya adalah melakukan transformasi data. Data mentah sering kali berada dalam format yang tidak sesuai dengan alat analisis yang akan digunakan. Sebagai contoh, data bisa dalam bentuk teks yang perlu diubah menjadi angka, atau data yang berada dalam skala berbeda harus diseragamkan.
Transformasi data adalah proses mengubah format atau struktur data agar lebih mudah dianalisis. Misalnya, jika data mentah mengandung tanggal dalam format yang berbeda-beda, Data Scientist perlu menyatukan format tanggal tersebut agar bisa dianalisis dengan lebih mudah. Transformasi data juga dapat mencakup pengelompokan kategori tertentu, seperti mengonversi status pelanggan dari “aktif” atau “tidak aktif” menjadi nilai biner (0 dan 1).
Transformasi ini juga mencakup teknik-teknik lain seperti:
- Konversi data teks menjadi numerik
- Pembuatan fitur baru (feature engineering) dari data mentah yang ada
- Penyederhanaan atau penggabungan kolom data yang serupa
3. Normalisasi Data (Data Normalization)
Dalam beberapa kasus, data mentah perlu dinormalisasi agar memiliki skala yang sama, terutama jika data tersebut berasal dari berbagai sumber atau memiliki rentang nilai yang berbeda. Normalisasi data adalah proses yang penting, terutama saat bekerja dengan algoritma machine learning yang sensitif terhadap perbedaan skala data.
Misalnya, data penjualan mungkin berada dalam rentang yang sangat besar (misalnya, dari 100 ribu hingga jutaan rupiah), sementara data lain seperti usia pelanggan berada dalam rentang yang jauh lebih kecil (misalnya, antara 18 hingga 65 tahun). Perbedaan skala ini bisa mempengaruhi hasil analisis, terutama jika model yang digunakan tidak bisa menangani perbedaan tersebut dengan baik.
Teknik normalisasi data yang umum digunakan meliputi:
- Min-Max Scaling. Mengubah skala data agar semua nilai berada dalam rentang tertentu, biasanya antara 0 dan 1.
- Z-score Normalization. Mengurangi rata-rata dan membagi dengan standar deviasi sehingga data memiliki distribusi dengan rata-rata 0 dan standar deviasi 1.
Dengan normalisasi yang tepat, Data Scientist dapat memastikan bahwa semua variabel memiliki kontribusi yang seimbang dalam model analisis.
4. Penggabungan Data (Data Integration)
Sering kali, Data Scientist harus bekerja dengan data dari berbagai sumber yang berbeda, seperti data internal perusahaan, data pelanggan dari media sosial, atau data penjualan dari aplikasi e-commerce. Data dari berbagai sumber ini perlu digabungkan agar bisa dianalisis secara keseluruhan.
Penggabungan data mencakup penyatuan berbagai dataset menjadi satu kesatuan yang koheren. Dalam proses ini, Data Scientist harus memastikan bahwa data dari berbagai sumber tersebut kompatibel dan memiliki format yang seragam. Tantangan yang sering dihadapi adalah menggabungkan data dengan kunci unik yang berbeda, seperti ID pelanggan yang berbeda-beda di setiap sistem.
Pengelolaan dan penggabungan data dari berbagai sumber ini sangat penting dalam analisis data skala besar yang melibatkan banyak dimensi informasi.
Kenali Pre-Processing Data, Pahami dengan Seksama
Pre-processing data adalah langkah awal dan sangat krusial dalam pengolahan data sebelum proses analisis dimulai. Tahapan ini bertujuan untuk membersihkan dan mempersiapkan data mentah sehingga siap digunakan dalam analisis lebih lanjut. Tanpa pre-processing yang tepat, hasil analisis bisa bias, tidak akurat, atau bahkan tidak dapat digunakan. Oleh karena itu, memahami proses pre-processing dengan seksama adalah kunci keberhasilan dalam pekerjaan seorang Data Scientist.
Berikut adalah beberapa tahapan penting dalam pre-processing data yang perlu kamu pahami:
1. Data Cleaning (Pembersihan Data)
Tahapan data cleaning adalah langkah pertama dalam pre-processing. Pada tahap ini, Data Scientist akan melakukan pembersihan data dari segala bentuk ketidakkonsistenan yang dapat mengganggu hasil analisis. Proses ini mencakup identifikasi, penghapusan, atau perbaikan kesalahan dalam data yang disebabkan oleh kesalahan entri, missing values, atau data duplikat.
- Menghapus atau Mengisi Missing Values.
Salah satu masalah umum pada data mentah adalah missing values atau nilai yang hilang. Ini bisa terjadi karena beberapa alasan, seperti kesalahan pengumpulan data atau tidak tersedianya informasi pada saat entri. Ada beberapa pendekatan yang dapat diambil untuk menangani masalah ini, termasuk menghapus baris yang memiliki nilai hilang atau mengisinya dengan nilai rata-rata, median, atau nilai prediktif. - Mengidentifikasi dan Menghapus Data Duplikat
Data yang duplikat bisa menyebabkan hasil analisis yang tidak akurat. Oleh karena itu, sangat penting bagi seorang Data Scientist untuk memeriksa dan menghapus data duplikat, sehingga dataset hanya berisi data yang valid dan relevan.
Proses data cleaning ini akan memastikan bahwa hanya data yang bersih dan siap digunakan yang akan dianalisis. Dalam Pelatihan dan Sertifikasi BNSP Data Scientist, kamu akan dilatih untuk memahami teknik-teknik pembersihan data ini secara mendalam, sehingga mampu meningkatkan kualitas dataset yang kamu kelola.
2. Data Integration (Integrasi Data)
Setelah data dibersihkan, langkah berikutnya dalam proses pre-processing adalah data integration. Pada tahap ini, data dari berbagai sumber yang berbeda akan digabungkan menjadi satu kesatuan yang koheren. Ini sangat penting, terutama ketika Data Scientist bekerja dengan data yang berasal dari berbagai sistem atau departemen dalam perusahaan.
- Penggabungan Data dari Berbagai Sumber
Dalam banyak kasus, Data Scientist harus menggabungkan data yang diperoleh dari berbagai platform, seperti data penjualan, data pelanggan, dan data operasional perusahaan. Tantangan terbesar di sini adalah memastikan bahwa semua data yang digabungkan memiliki format dan struktur yang kompatibel, sehingga bisa dianalisis secara efektif. - Penyatuan Format Data
Ketika data berasal dari berbagai sumber, formatnya mungkin berbeda-beda. Misalnya, data tanggal bisa saja disimpan dalam berbagai format (DD-MM-YYYY atau MM-DD-YYYY). Penyatuan format ini penting agar analisis dapat dilakukan dengan konsisten.
Dalam Pelatihan dan Sertifikasi BNSP Data Scientist, kamu akan diajarkan cara melakukan integrasi data ini secara efisien, sehingga kamu mampu bekerja dengan data dalam skala besar dan dari berbagai sumber tanpa kehilangan kualitas analisis.
3. Transformasi Data (Data Transformation)
Tahap data transformation adalah proses mengubah format atau struktur data agar lebih sesuai untuk keperluan analisis. Data mentah yang diperoleh dari berbagai sumber sering kali memerlukan transformasi sebelum bisa digunakan dalam algoritma machine learning atau model statistik.
- Konversi Data Teks Menjadi Numerik. Dalam banyak kasus, data yang berbentuk teks perlu diubah menjadi bentuk numerik agar bisa diolah oleh algoritma analisis data. Misalnya, dalam dataset pelanggan, status “aktif” atau “tidak aktif” dapat dikonversi menjadi 1 atau 0.
- Feature Engineering. Data Scientist sering kali membuat fitur baru dari data yang ada untuk membantu memperkuat analisis. Misalnya, menghitung rasio antara dua kolom data yang ada bisa menjadi fitur tambahan yang memberi wawasan lebih dalam analisis.
- Penyederhanaan Data. Terkadang, data yang terlalu kompleks bisa sulit dianalisis. Data Scientist harus mampu menyederhanakan data ini tanpa mengurangi kualitas informasi yang terkandung di dalamnya.
Tahap transformasi ini sangat penting dalam analisis data modern. Dengan mengikuti Pelatihan dan Sertifikasi BNSP Data Scientist, kamu akan mendapatkan pemahaman mendalam tentang teknik-teknik transformasi data, yang merupakan keterampilan kunci bagi setiap Data Scientist.
4. Data Reduction (Mengurangi Data)
Tahap terakhir dalam pre-processing adalah data reduction atau pengurangan data. Tahapan ini bertujuan untuk menyederhanakan data dengan cara mengurangi dimensi atau ukuran dataset tanpa menghilangkan informasi penting yang terkandung di dalamnya. Data reduction sangat berguna saat bekerja dengan dataset yang besar dan kompleks, karena dapat mempercepat proses analisis tanpa mengorbankan akurasi.
- PCA (Principal Component Analysis)
PCA adalah salah satu teknik pengurangan dimensi yang populer. Dengan PCA, Data Scientist dapat mengurangi jumlah fitur dalam dataset sambil mempertahankan sebagian besar variabilitas atau informasi dalam data tersebut. - Sampling
Teknik lain dalam pengurangan data adalah sampling, yaitu memilih subset dari data yang mewakili keseluruhan dataset. Dengan menggunakan teknik ini, Data Scientist bisa mempercepat proses analisis ketika berhadapan dengan dataset yang sangat besar. - Eliminasi Fitur yang Tidak Relevan
Dalam beberapa kasus, ada fitur atau variabel dalam dataset yang tidak relevan atau tidak memberikan kontribusi signifikan terhadap analisis. Menghapus fitur ini akan membuat dataset lebih efisien untuk diproses.
Dengan teknik pengurangan data yang tepat, kamu dapat bekerja lebih efisien dengan data yang lebih kecil namun tetap memberikan hasil yang akurat. Pelatihan dan Sertifikasi BNSP Data Scientist juga akan mengajarkanmu bagaimana menggunakan teknik-teknik pengurangan data ini secara efektif.
Memahami dan menerapkan langkah-langkah pre-processing data dengan baik adalah keterampilan yang sangat penting bagi seorang Data Scientist. Tanpa pre-processing yang benar, analisis data akan menjadi kurang akurat, tidak dapat diandalkan, dan bahkan bisa menghasilkan kesimpulan yang salah.
Klasifikasi Data: Apa Saja dan Bagaimana Hal Tersebut Dapat Digunakan?
Klasifikasi data adalah teknik analisis yang digunakan untuk mengelompokkan data ke dalam kategori atau kelas yang telah ditentukan sebelumnya. Dalam analisis data, tujuan utama klasifikasi adalah memprediksi kategori atau label dari data yang baru berdasarkan pola yang telah diidentifikasi dari data historis. Teknik ini sangat umum dalam berbagai aplikasi, seperti pengenalan wajah, diagnosis medis, analisis sentimen, hingga deteksi penipuan.
Terdapat beberapa metode yang digunakan dalam klasifikasi data. Setiap metode memiliki kelebihan dan kekurangan sesuai jenis data dan kebutuhan analisis. Mari kita bahas beberapa metode populer yang sering digunakan oleh seorang Data Scientist:
1. Decision Tree Model
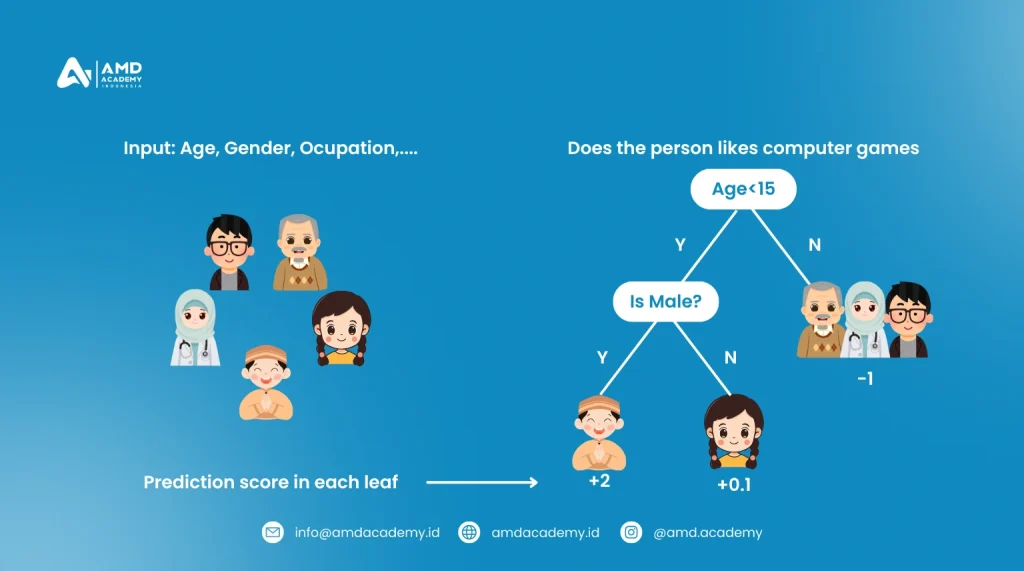
Decision tree adalah salah satu algoritma klasifikasi yang paling mudah dipahami dan diimplementasikan. Model ini bekerja dengan membangun struktur pohon di mana setiap node internal mewakili fitur dari dataset, setiap cabang mewakili aturan keputusan, dan setiap daun mewakili hasil klasifikasi.
- Bagaimana Cara Kerjanya? Decision tree membagi dataset menjadi subset berdasarkan nilai fitur tertentu, dengan menggunakan aturan keputusan. Setiap pembagian berusaha untuk memaksimalkan homogeneitas dalam setiap subset (misalnya, menggunakan metrik seperti Gini index atau entropy).
- Contoh Penggunaan: Decision tree sering digunakan dalam bidang medis untuk memprediksi apakah seorang pasien memiliki penyakit tertentu berdasarkan gejala mereka.
Keunggulan utama dari decision tree adalah interpretasinya yang mudah dan visualisasi yang intuitif, meskipun terkadang bisa rentan terhadap overfitting pada dataset yang besar.
2. Support Vector Machine (SVM)
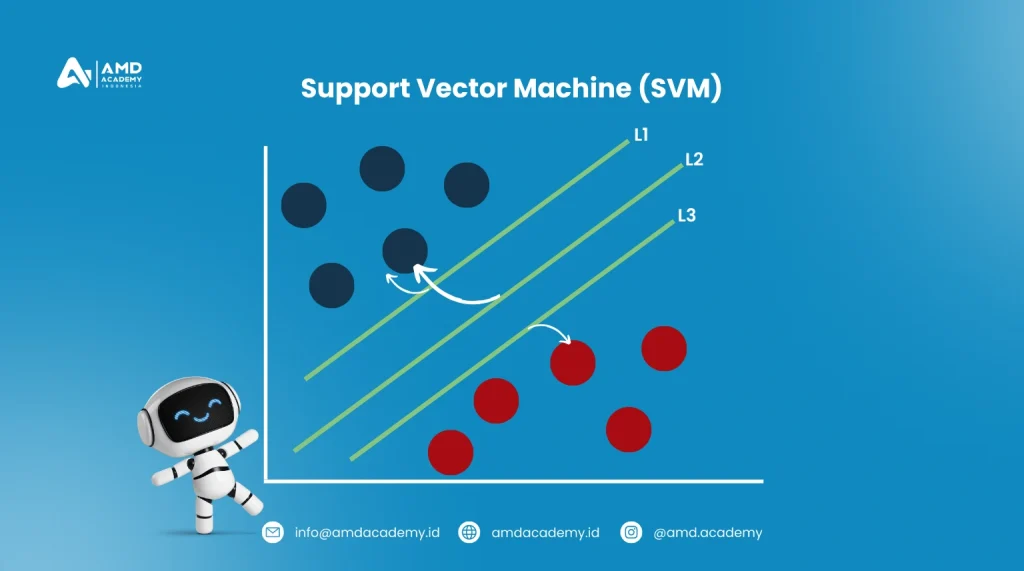
Support Vector Machine (SVM) adalah metode klasifikasi yang mencari garis atau bidang terbaik (dalam kasus multi-dimensi) yang memisahkan dua kelas dengan margin maksimal. Algoritma ini sangat efektif untuk menangani data yang tidak terpisah secara linier. Trik kernel digunakan untuk memetakan data ke dimensi lebih tinggi.
- Bagaimana Cara Kerjanya? SVM membagi data ke dalam dua kelas dengan mencari hyperplane yang memaksimalkan jarak antara dua kelas terdekat (yang disebut support vectors). Jika data tidak dapat dipisahkan secara linier, SVM dapat menggunakan kernel trick untuk menangani kasus ini.
- Contoh Penggunaan: SVM sering digunakan dalam klasifikasi citra, seperti dalam pengenalan pola tulisan tangan atau wajah.
Keunggulan SVM adalah kemampuannya menangani data dalam dimensi tinggi dan cocok untuk dataset yang kompleks, meskipun agak lambat pada dataset besar.
3. Naive Bayes Classifier
Naive Bayes adalah metode klasifikasi yang didasarkan pada Teorema Bayes dengan asumsi independensi antar fitur. Meskipun asumsi independensi ini jarang benar dalam praktik, algoritma ini sering memberikan hasil yang sangat baik, terutama dalam aplikasi klasifikasi teks.
- Bagaimana Cara Kerjanya? Naive Bayes menghitung probabilitas setiap kelas berdasarkan fitur yang ada dan memprediksi kelas dengan probabilitas tertinggi. Asumsi utama di sini adalah bahwa setiap fitur memberikan kontribusi yang independen terhadap probabilitas kelas.
- Contoh Penggunaan: Naive Bayes sering digunakan untuk klasifikasi email (spam vs. non-spam) atau analisis sentimen.
Keunggulan dari Naive Bayes adalah kecepatannya dalam menghitung probabilitas, meskipun asumsi independensi antar fitur dapat menjadi kelemahan jika data sangat bergantung pada keterkaitan antar fitur.
4. Random Forest
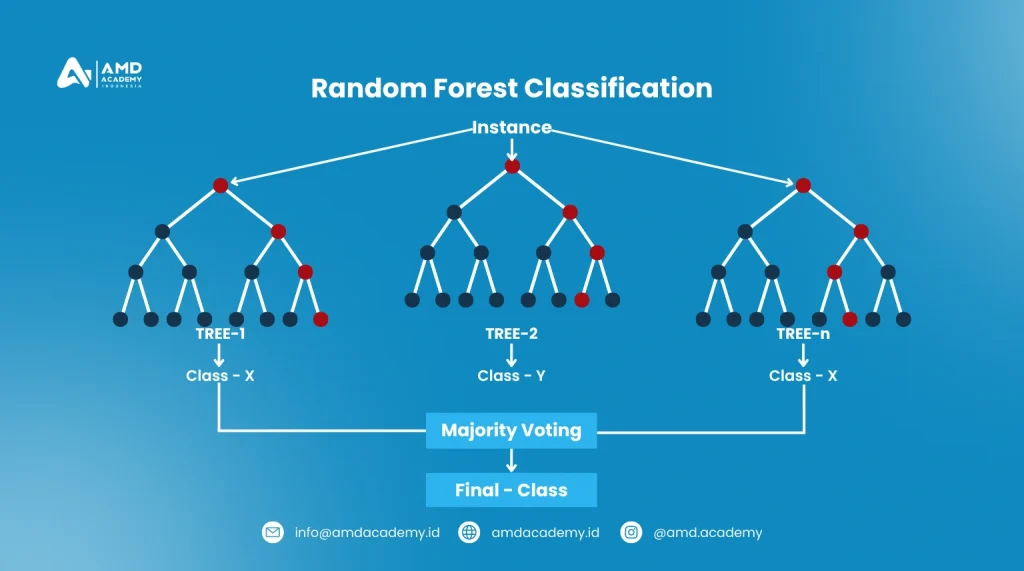
Random Forest adalah metode klasifikasi yang menggabungkan beberapa decision tree untuk menghasilkan hasil yang lebih akurat dan stabil. Ini adalah metode ensemble learning di mana banyak pohon keputusan dilatih pada subset acak dari dataset, dan hasil akhir ditentukan melalui pemungutan suara mayoritas dari semua pohon.
- Bagaimana Cara Kerjanya? Random forest membuat beberapa decision tree dari subset data yang dipilih secara acak dan menggunakan rata-rata atau voting mayoritas dari semua pohon untuk membuat prediksi.
- Contoh Penggunaan: Random forest sering digunakan dalam bidang keuangan untuk mendeteksi penipuan atau dalam analisis genomik untuk memprediksi penyakit.
Keunggulan utama random forest adalah ketahanannya terhadap overfitting dan kemampuannya menangani dataset besar dan kompleks, meskipun pada dataset yang sangat besar, waktu komputasi bisa menjadi masalah.
5. K-Nearest Neighbor (K-NN)
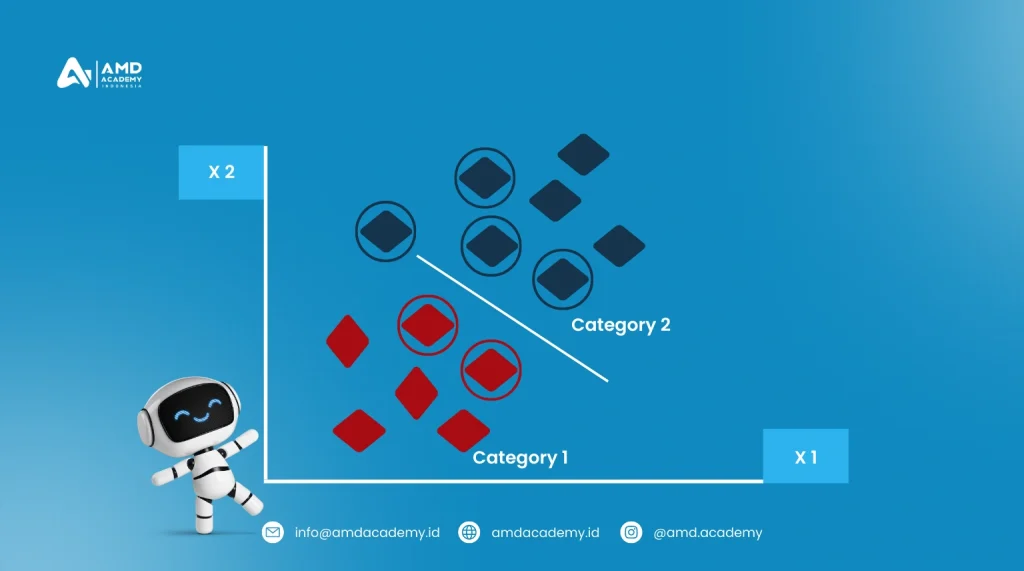
K-Nearest Neighbor (K-NN) adalah metode klasifikasi yang sangat intuitif dan mudah diimplementasikan. Algoritma ini mengklasifikasikan data baru berdasarkan jarak terdekatnya ke data yang sudah ada. K-NN merupakan lazy learner karena tidak mempelajari model secara eksplisit, melainkan hanya menyimpan dataset dan melakukan klasifikasi berdasarkan tetangga terdekat.
- Bagaimana Cara Kerjanya? K-NN menghitung jarak antara data baru dan semua data yang ada, dan kemudian mengklasifikasikan data baru berdasarkan mayoritas dari K tetangga terdekatnya.
- Contoh Penggunaan: K-NN digunakan dalam sistem rekomendasi produk, di mana produk serupa direkomendasikan berdasarkan kesamaan preferensi pengguna sebelumnya.
K-NN sangat mudah dipahami dan diterapkan, tetapi kecepatan pemrosesannya bisa menjadi lambat pada dataset yang sangat besar.
6. Logistic Regression
Logistic regression adalah metode klasifikasi yang digunakan untuk memprediksi probabilitas suatu data termasuk dalam satu dari dua kelas. Meskipun disebut “regresi,” metode ini digunakan untuk klasifikasi biner dengan hasil yang diklasifikasikan sebagai 0 atau 1 berdasarkan fungsi logistik.
- Bagaimana Cara Kerjanya? Logistic regression memperkirakan probabilitas sebuah data termasuk ke dalam kelas tertentu menggunakan fungsi sigmoid, yang memetakan nilai dari variabel input ke rentang antara 0 dan 1.
- Contoh Penggunaan: Logistic regression digunakan secara luas dalam aplikasi medis untuk memprediksi apakah seorang pasien memiliki penyakit tertentu (misalnya, diabetes) berdasarkan faktor-faktor risiko seperti usia dan gaya hidup.
Keunggulan logistic regression adalah kemampuannya menangani dataset besar dan memberikan interpretasi yang jelas, meskipun algoritma ini kurang efektif jika ada banyak fitur yang tidak berhubungan atau terlalu kompleks.
Klasifikasi data adalah komponen penting dalam analisis data modern, dengan berbagai algoritma yang dapat disesuaikan dengan jenis data dan kebutuhan spesifik. Teknik seperti decision tree, SVM, Naive Bayes, random forest, K-NN, dan logistic regression semuanya menawarkan kelebihan yang unik tergantung pada kasus penggunaan dan jenis data yang dianalisis.
Melalui Pelatihan dan Sertifikasi BNSP Data Scientist, kamu akan mempelajari berbagai metode klasifikasi ini secara mendalam dan praktis, sehingga kamu siap mengaplikasikannya di dunia kerja nyata. Dari memahami teori di balik setiap metode hingga menerapkannya dalam proyek analisis data yang nyata, pelatihan ini akan mempersiapkanmu untuk menjadi seorang Data Scientist yang andal dan profesional.
Mengembangkan Karier Melalui Pelatihan dan Sertifikasi BNSP Data Scientist
Meningkatnya permintaan akan profesi Data Scientist tidak serta-merta mudah dipenuhi. Dibutuhkan kemampuan analisis yang kuat, pemahaman mendalam tentang statistik, serta kemampuan berpikir kritis untuk mengolah data menjadi informasi strategis. Namun kabar baiknya, kamu bisa mempelajarinya melalui Pelatihan dan Sertifikasi BNSP Data Scientist dari AMD Academy. Program ini dirancang untuk membekali peserta dengan keahlian teknis dan praktis, mulai dari pengumpulan data, pre-processing, hingga penerapan teknik machine learning dan visualisasi data.
Pelatihan ini juga memberikan pengalaman belajar yang relevan dengan kebutuhan industri saat ini. Kamu akan dibimbing oleh para ahli berpengalaman di bidang data, serta mendapatkan pemahaman tentang bagaimana analisis data diterapkan di berbagai sektor, seperti teknologi, keuangan, kesehatan, dan manufaktur. Pendekatan pembelajarannya bersifat praktis sehingga hasilnya langsung bisa digunakan di dunia kerja.
Dengan mengikuti pelatihan ini, kamu tidak hanya memperoleh keterampilan analisis data, tetapi juga sertifikasi resmi dari BNSP sebagai bukti kompetensi profesional yang diakui secara nasional. Sertifikasi ini akan meningkatkan daya saingmu di dunia kerja sekaligus membuka peluang karier yang lebih luas. Jadi, jika kamu tertarik untuk mengembangkan karier di bidang data, inilah langkah awal yang tepat untuk menjadi profesional andal di era digital berbasis data.
Bergabunglah Bersama Pelatihan dan Sertifikasi BNSP Data Scientist dengan Modul Lengkap di AMD Academy yang Sudah Berstandar SKKNI
Pelatihan dan Sertifikasi BNSP Data Scientist di AMD Academy dirancang sesuai dengan Standar Kompetensi Kerja Nasional Indonesia (SKKNI), yang merupakan acuan utama dalam memastikan bahwa lulusan pelatihan memiliki kemampuan yang sesuai dengan kebutuhan industri. Standar ini juga menjamin bahwa kompetensi yang diajarkan sudah memenuhi kriteria yang diperlukan untuk bersaing dalam pasar kerja global.

Berikut adalah modul pelatihan yang akan kamu pelajari di AMD Academy:
1. Menentukan Label Dat
Pada modul ini, kamu akan mempelajari cara menentukan label yang tepat untuk data yang diolah. Labeling adalah proses kritis dalam machine learning, di mana setiap data diberi klasifikasi atau identifikasi tertentu yang digunakan dalam proses analisis lebih lanjut.
2. Mengumpulkan Dat
Peserta akan dibekali dengan pengetahuan tentang berbagai teknik pengumpulan data dari sumber yang berbeda-beda, seperti API, web scraping, dan database internal. Data yang dikumpulkan harus relevan dan dapat diandalkan untuk analisis lebih lanjut.
3. Menelaah dan Memvalidasi Data
Setelah data terkumpul, penting untuk melakukan validasi agar data tersebut sesuai dengan kebutuhan analisis. Dalam sesi ini, peserta akan belajar cara mengecek kualitas data, menemukan outlier, serta menangani data yang tidak lengkap atau tidak konsisten.
4. Menentukan Objek Data
Modul ini berfokus pada pemilihan objek data yang tepat sesuai dengan tujuan analisis. Kamu akan belajar cara mengidentifikasi variabel-variabel penting yang akan mempengaruhi hasil analisis.
5. Membersihkan dan Mengkonstruksi Data
Sebelum memulai proses analisis, data harus dibersihkan dari kesalahan atau anomali. Modul ini mengajarkan teknik data cleaning, termasuk menghapus duplikasi, menangani missing values, serta transformasi data agar siap dianalisis.
6. Membangun Model
Pada tahapan ini, peserta akan belajar tentang teknik membangun model analitik dan machine learning, seperti decision tree, random forest, dan logistic regression. Setiap model akan dievaluasi berdasarkan efektivitasnya dalam menyelesaikan masalah tertentu.
7. Mengevaluasi Hasil Pemodelan
Setelah model dibangun, langkah selanjutnya adalah mengevaluasi hasilnya. Modul ini membahas berbagai metrik evaluasi seperti accuracy, precision, recall, dan F1-score untuk memastikan model yang dibangun memberikan hasil yang optimal.
Seluruh modul dalam Pelatihan dan Sertifikasi BNSP Data Scientist di AMD Academy sudah disesuaikan dengan standar SKKNI. Dengan demikian, kamu akan mendapatkan kompetensi yang diakui secara nasional dan siap bersaing di industri data science yang semakin berkembang. Melalui pelatihan ini, kamu tidak hanya belajar teori tetapi juga praktik langsung yang berguna dalam dunia kerja.
Dapatkan kesempatan untuk mengikuti Pelatihan dan Sertifikasi BNSP Data Scientist di AMD Academy dan siapkan dirimu untuk berkarir di bidang yang penuh peluang ini.
Ayo Tingkatkan Skillmu dengan Pelatihan dan Sertifikasi BNSP Data Scientist Bersama AMD Academy
Jangan lewatkan kesempatan untuk meningkatkan keterampilanmu di bidang data dengan mengikuti Pelatihan dan Sertifikasi BNSP Data Scientist bersama AMD Academy. Program ini dirancang untuk membantu kamu memahami setiap aspek dalam pengolahan dan analisis data, mulai dari pre-processing hingga teknik klasifikasi data. Dengan mengikuti program ini, kamu tidak hanya akan menguasai keterampilan teknis, tetapi juga mendapatkan sertifikasi yang diakui secara nasional oleh Badan Nasional Sertifikasi Profesi (BNSP).
Pelatihan dan Sertifikasi BNSP Data Scientist dari AMD Academy akan membekali kamu dengan pengetahuan dan keterampilan yang diperlukan untuk menjadi Data Scientist yang handal. Kunjungi amdacademy.id untuk informasi lebih lanjut dan daftarkan dirimu sekarang juga! Jangan lewatkan peluang untuk berkarir di bidang data yang terus berkembang ini.Hubungi kami di sini!
Author: Sesario Kevin Putratama (DTS Batch 07)
Editor: Aulia Fathir Rizqi

slot365 xây dựng uy tín dựa trên sự hài lòng của hơn 5 triệu thành viên đang hoạt động hàng ngày trên toàn châu Á. TONY06-05