
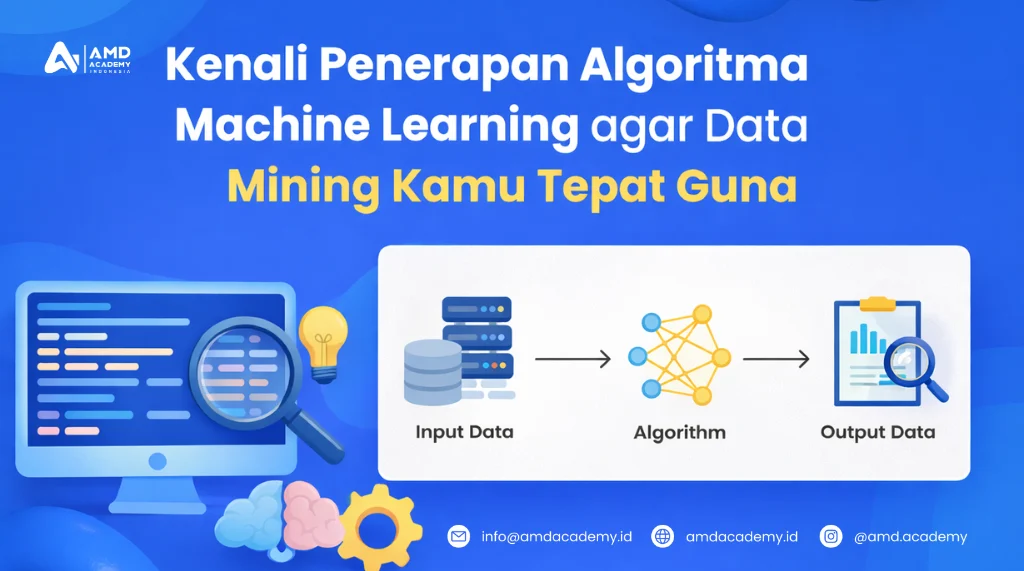
Pelatihan dan Sertifikasi BNSP – Memasuki era digital yang serba cepat, data jadi bahan bakar penting untuk bisnis. Karena itu, keputusan berbasis data (bukan sekadar intuisi) semakin dibutuhkan. Di sisi lain, data terus bertambah setiap hari. Akibatnya, banyak perusahaan kesulitan memilah mana informasi yang benar-benar berguna.
Di sinilah data science, machine learning (ML), dan data mining berperan. Ketiganya membantu mengolah data besar menjadi insight yang bisa dipakai untuk strategi bisnis. Selain itu, hasil analisis yang rapi membuat perencanaan lebih akurat.
Artikel ini membahas dasar machine learning, alur kerja data mining, serta contoh algoritma yang sering dipakai. Pada akhirnya, kamu juga akan melihat kompetensi yang dibutuhkan untuk menjadi data scientist, termasuk lewat Pelatihan dan Sertifikasi BNSP.
Machine Learning dan Data Mining, Apa Hubungannya?
Machine learning adalah bagian dari kecerdasan buatan (artificial intelligence atau AI). Intinya, komputer belajar dari data untuk membuat prediksi atau keputusan. Jadi, sistem tidak perlu diprogram ulang untuk setiap kasus baru.
Sementara itu, data mining adalah proses menggali pola dari data. Tujuannya sederhana yaitu menemukan informasi tersembunyi yang bermanfaat. Misalnya, pola belanja pelanggan atau tren penjualan musiman.
Dengan kata lain, data mining sering memakai algoritma machine learning untuk menemukan pola. Namun, data mining juga mencakup langkah yang lebih luas, seperti menyiapkan data dan menafsirkan hasilnya agar relevan untuk bisnis.
Kenali Lebih Dekat Machine Learning
Secara umum, machine learning dibagi menjadi tiga jenis. Masing-masing dipakai untuk kebutuhan yang berbeda. Oleh karena itu, penting memahami konteks masalah sebelum memilih metode.
1) Supervised Learning (Belajar dari Data Berlabel)
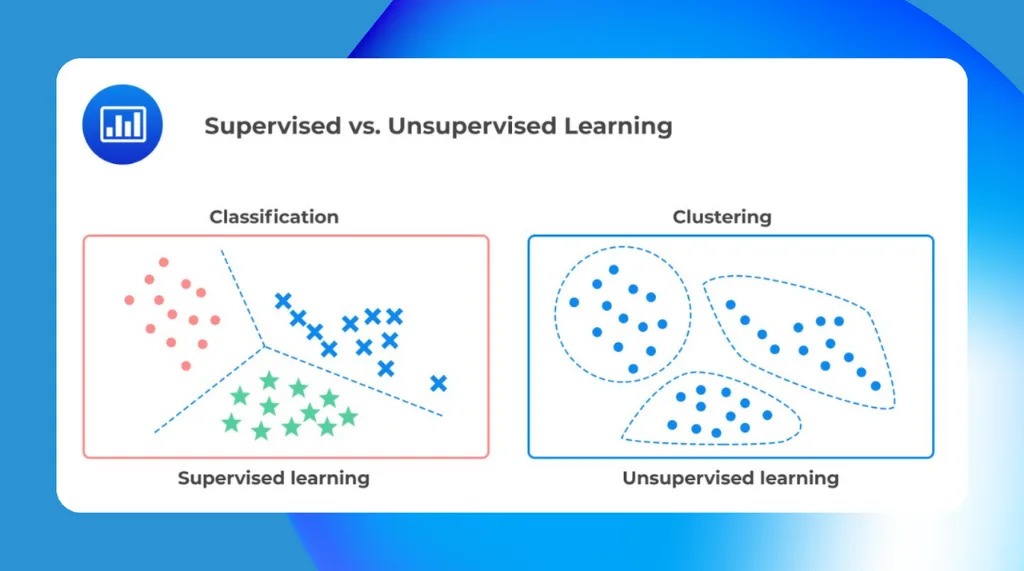
Pada supervised learning, data latih punya “jawaban” atau label. Model belajar dari contoh yang sudah diketahui hasilnya. Setelah itu, model dipakai untuk memprediksi data baru.
Contoh penerapan:
- Prediksi penjualan bulan depan.
- Menilai risiko kredit.
- Mengklasifikasikan email spam dan non-spam.
Algoritma yang sering digunakan:
- Linear Regression
- Logistic Regression
- Decision Tree
- Random Forest
Kelebihannya, prediksi bisa sangat akurat jika datanya bagus. Namun, data berlabel sering sulit dikumpulkan dan butuh waktu.
2) Unsupervised Learning (Belajar dari Data Tanpa Label)
Berbeda dari sebelumnya, unsupervised learning tidak punya label. Model mencari pola secara otomatis. Karena itu, metode ini cocok untuk eksplorasi data.
Contoh penerapan:
- Segmentasi pelanggan berdasarkan kebiasaan belanja.
- Mengelompokkan produk berdasarkan kemiripan.
- Menemukan pola asosiasi belanja (market basket).
Algoritma yang umum:
- K-Means
- Hierarchical Clustering
- Apriori (untuk asosiasi)
Metode ini fleksibel untuk data mentah. Namun, hasilnya perlu interpretasi yang lebih hati-hati.
3) Reinforcement Learning (Belajar dari Reward dan Penalti)
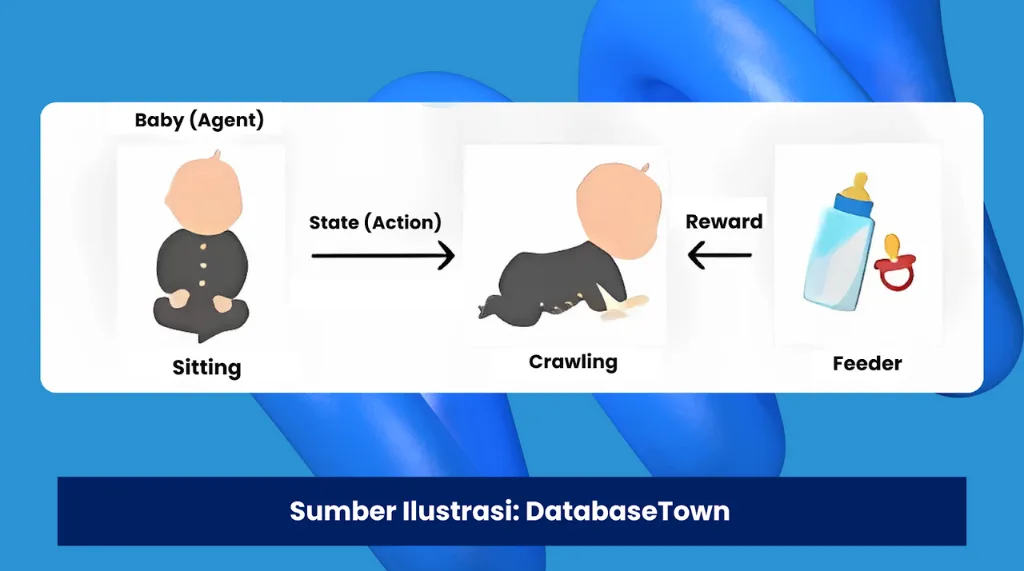
Reinforcement learning belajar lewat “coba-coba” dalam suatu lingkungan. Jika keputusan benar, model mendapat reward. Jika salah, ada penalti. Dengan demikian, model berusaha memilih langkah terbaik dari waktu ke waktu.
Contoh penerapan:
- Sistem rekomendasi yang makin personal.
- Robotika dan otomasi.
- Gim AI.
Algoritma yang sering dibahas:
- Q-Learning
- SARSA
- Deep Q Network (DQN)
Data Mining: Bagaimana Prosesnya?
Data mining bukan cuma “jalankan model lalu selesai”. Prosesnya bertahap. Selain itu, kualitas hasil sangat dipengaruhi oleh kualitas data.
1) Preprocessing Data (Menyiapkan Data)
Tahap ini sering paling memakan waktu. Namun, tahap ini juga yang paling menentukan.
Beberapa langkah penting:
- Pembersihan data: menghapus duplikat, memperbaiki nilai yang salah, dan membuang data tidak relevan.
- Menangani data kosong (missing value): diisi dengan mean/median/modus, atau teknik imputasi.
- Normalisasi/standarisasi: menyamakan skala nilai agar model tidak bias.
Jika preprocessing buruk, hasil analisis bisa menyesatkan. Karena itu, data yang rapi adalah pondasi utama.
2) Penerapan Algoritma Data Mining (Modeling)
Di tahap ini, data yang sudah siap dipakai untuk menemukan pola. Pemilihan algoritma harus sesuai tujuan. Misalnya, segmentasi lebih cocok memakai clustering.
Berikut algoritma yang paling umum digunakan.
A. Klasifikasi (Classification)
Klasifikasi dipakai untuk memprediksi kategori. Contohnya: “transaksi aman” vs “transaksi mencurigakan”.
Algoritma populer:
- Decision Tree: mudah dipahami karena berbentuk aturan “jika-maka”. Namun, bisa overfitting jika pohon terlalu dalam.
- Naive Bayes: cepat dan cocok untuk teks. Walau asumsi fiturnya “independen”, sering tetap efektif.
- Support Vector Machine (SVM): kuat untuk data dengan batas pemisah yang jelas. Akan tetapi, tuning parameter bisa lebih rumit.
B. Clustering
Clustering mengelompokkan data tanpa label. Metode ini sering dipakai untuk segmentasi pelanggan.
Algoritma populer:
- K-Means: cepat dan sederhana. Namun, kamu harus menentukan jumlah cluster (k) di awal.
- Hierarchical Clustering: menghasilkan dendrogram (pohon hubungan). Kelebihannya, tidak wajib menentukan k sejak awal. Sayangnya, lebih berat untuk data besar.
C. Regresi (Regression)
Regresi dipakai untuk memprediksi angka. Misalnya, memprediksi jumlah penjualan atau harga.
Jenis regresi yang sering dipakai:
- Linear Regression: cocok untuk hubungan yang relatif lurus.
- Logistic Regression: sebenarnya untuk klasifikasi biner (ya/tidak) dengan output probabilitas.
- Polynomial Regression: dipakai jika hubungan data membentuk kurva. Namun, risiko overfitting bisa meningkat.
D. Asosiasi (Association)
Asosiasi mencari barang atau kejadian yang sering muncul bersama. Contohnya, pelanggan yang beli roti sering beli selai.
Algoritma populer:
- Apriori: mencari kombinasi item yang sering muncul. Metode ini bisa berat jika data sangat besar.
- FP-Growth: umumnya lebih cepat karena memakai struktur pohon (FP-Tree). Meski begitu, kebutuhan memori bisa lebih tinggi.
3) Evaluasi Model (Mengukur Kualitas Hasil)
Model yang bagus harus bisa diukur. Karena itu, evaluasi wajib dilakukan sebelum dipakai untuk keputusan bisnis.
Metrik umum untuk klasifikasi:
- Akurasi: mudah dipahami, tetapi bisa menipu jika data tidak seimbang.
- Precision: seberapa tepat prediksi positif.
- Recall: seberapa banyak kasus positif yang berhasil ditangkap.
- F1-Score: menyeimbangkan precision dan recall.
Metrik umum untuk regresi:
- MAE (Mean Absolute Error): rata-rata selisih absolut.
- RMSE (Root Mean Squared Error): lebih sensitif terhadap outlier.
Kenapa Data Mining Penting untuk Bisnis?
Data mining membuat keputusan lebih terarah. Selain itu, perusahaan bisa bergerak lebih cepat karena punya dasar yang jelas.
Manfaat yang paling sering dirasakan:
- Memprediksi tren pasar berdasarkan data historis.
- Memahami perilaku pelanggan lewat segmentasi dan pola belanja.
- Mengurangi risiko seperti fraud, churn, atau gagal bayar.
- Meningkatkan penjualan lewat strategi cross-selling dan upselling.
Dengan begitu, data bukan sekadar arsip. Data berubah jadi aset yang menghasilkan nilai.
Keterampilan yang Dibutuhkan Data Scientist
Agar penerapan ML dan data mining tepat guna, kamu perlu kombinasi kemampuan teknis dan pemahaman bisnis. Oleh karena itu, pembelajaran sebaiknya mencakup praktik nyata, bukan teori saja.
Kemampuan yang umumnya wajib:
- Menentukan label dan target analisis.
- Mengumpulkan data dari berbagai sumber.
- Menelaah data (exploratory data analysis / EDA) untuk memahami pola awal.
- Memvalidasi kualitas data.
- Menentukan variabel penting (feature selection).
- Membersihkan dan mengkonstruksi data (feature engineering).
- Membangun model dan melakukan tuning.
- Mengevaluasi hasil dan menjelaskan dampaknya untuk bisnis.
Modul Pelatihan dan Sertifikasi BNSP Data Scientist Berstandar SKKNI

Untuk kamu yang ingin belajar lebih terarah, Pelatihan dan Sertifikasi BNSP Data Scientist berstandar SKKNI bisa jadi langkah strategis. Program seperti ini biasanya membantu peserta memahami proses dari awal sampai akhir. Selain itu, sertifikasi BNSP dapat memperkuat kredibilitas di dunia kerja.
Materi yang umumnya dibahas mencakup:
- Menentukan label data
- Mengumpulkan data
- Menelaah data
- Memvalidasi data
- Menentukan objek/variabel data
- Membersihkan data
- Mengkonstruksi data
- Membangun model machine learning
- Mengevaluasi hasil pemodelan
Raih Karier Data Scientist lewat Pelatihan dan Sertifikasi BNSP di AMD Academy

Kebutuhan talenta data terus naik di banyak industri. Karena itu, mengikuti Pelatihan dan Sertifikasi BNSP Data Scientist di AMD Academy dapat membantu kamu naik level lebih cepat.
Program ini dirancang agar kamu:
- Paham konsep machine learning dan data mining dengan bahasa yang mudah.
- Bisa praktik membangun model untuk kasus nyata.
- Mengerti cara membaca metrik evaluasi dengan benar.
- Siap menghadapi kebutuhan industri yang dinamis.
Pada akhirnya, sertifikasi BNSP bisa menjadi nilai tambah saat melamar kerja atau naik jabatan. Jangan lewatkan kesempatan untuk meningkatkan kompetensi kamu. Hubungi kami di sini!
